
자연어처리와 같은 순서 데이터를 처리하기 위한 딥러닝 모델 구조인 RNN과,
RNN의 단점을 개선한 버전인 LSTM과 GRU에 대해 살펴보도록 하겠다.
1. RNN
1-1. RNN이란?
RNN : Recurrent Neural Network의 약자로, Sequence data를 처리하기에 좋은 구조이다.
여기서 Sequence data는 어떠한 순서를 가진 데이터를 의미한다.
(참고) Sequence data와 관련된 NLP task 활용 예시는 다음과 같다.

- 입력과 출력이 모두 sequence data이지만 길이가 다른 경우 : e.g. machine translation
- 길이가 같은 경우 : e.g. name entity recognition
- 입력과 출력 중 하나만 sequence data인 경우 : e.g. Video activity recognition
1-2. 기본적인 구조 및 용어 설명

보통 왼쪽 이미지가 RNN을 검색했을 때 나오는 일반적인 자료인데, 이를 펼치면 오른쪽과 같은 이미지이다. 이 이미지에 대한 설명은 아래와 같다.
- 각 단어에 대한 시퀀스를 Xt로 표현한다. 즉 X1는 첫 번째 단어, X2는 두 번째 단어 … 를 의미한다.
- 초록색은 입력층, 파란색은 은닉층, 분홍색은 출력층을 의미한다.
- RNN은 과거 정보(V)와 현재 정보(U)를 모두 반영 : 은닉층의 결과를 출력층에도 보내고, 그 다음 시퀀스의 은닉층으로도 보내면서 과거 정보를 잃지 않도록 해준다. 이렇게 함으로써 자동으로 순서 정보가 저장된다.
RNN 아키텍쳐에는 다음과 같은 종류가 있다.
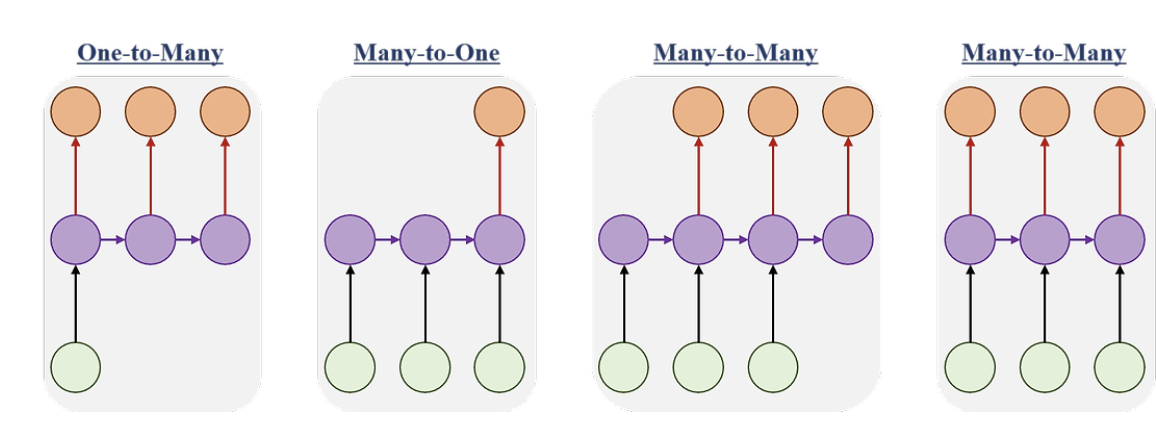
one to many : image captioning 등에 활용된다.
many to one : 감정 분류, 스팸 메일 분류 등에 활용된다.
many to many : machine translation, video recognition 등에 활용된다.
1-3. 가중치 공유
RNN의 핵심 아이디어는 동일한 가중치를 시퀀스의 다양한 위치에서 반복적으로 적용하는 것이다. (가중치 공유)


- X1일 때와 X2일 때, .. Xn일때 모두 같은 U, W, b 파라미터를 공유한다. 따라서 모든 시퀀스를 돈 다음 파라미터를 업데이트 하는 방식으로 진행된다. DNN의 경우 각 계층에서 파라미터가 각기 다르게 학습되므로 RNN만의 특징이라고 할 수 있다.

가중치 공유를 하면 다음과 같은 이점이 있다.
- 학습 파라미터의 수 감소 : 서로 다른 가중치 파라미터를 가진다면 시퀀스가 길어질수록 모델의 크기가 기하급수적으로 커질 것이다. 따라서 시퀀스의 길이와 상관없이 모델의 크기를 유지할 수 있다는 점에서 장점이 있다.
- 일반화 능력 향상 : 감정 분석을 할 때, 다음 두 문장에 대해서 학습을 한다고 해보자. “어제 나는 영화를 보았다. 정말 좋았다.”, "나는 영화를 어제 보았다. 정말 좋았다." 이 두 문장은 “어제”의 순서가 다를 뿐 같은 문장이다. 그런데 이를 전체적으로 보지 않고 각 단어에 따라 별도로 학습한다면 두 문장의 형태가 다르게 해석될 것이다.이를 통해, 모델이 보지 못한 시퀀스 데이터에 대해서도 더욱 효과적으로 이해할 수 있도록 해준다.
1-3. Backpropagation Through Time (BPTT)
BPTT는 RNN 구조에서 기울기를 계산할 때 사용하는 용어이다. 다른 역전파 과정과 거의 유사하나 시간의 흐름에 따라 처리되는 sequential data의 특성을 반영한 용어라고 할 수 있다.

위 그림을 일반화하면 아래와 같다.

2. LSTM, GRU
2-1. RNN의 한계점
1-3에서 RNN에서 역전파를 구하는 계산을 Backpropagation through time (BPTT)이라고 했었다. RNN 구조 특성상 전체 sequence를 모두 읽은 이후 역전파가 이루어진다.
그런데 이렇게 역전파를 계산할 때 Vanishing gradients problem이 있다. 그 이유는 chain rule 때문이다.

역전파를 구하는 과정에서 chain rule에 의해 다음 미분값이 반복적으로(등비수열 형태로) 곱해진다.

gradient exploding : W가 1보다 크다면 발산(무한대)
gradient vanishing : W가 1보다 작다면 점차 0으로 수렴
⇒ 0으로 수렴하게 되면, 가중치 업데이트가 더 이상 이루어지지 않아 학습이 제대로 이뤄지지 않는다.
⇒ 그리고 이러한 문제는 RNN의 시퀀스가 길어질 수록 발생할 확률이 높아지며, 결과적으로 장기 의존성 문제가 발생한다.
장기 의존성 문제 (the problem of Long‑Term Dependencies) : 과거의 정보가 제대로 반영이 되지 못하는 현상을 의미한다.
예를 들어, 다음에 올 단어를 예측하는 task에서
- 모스크바에 여행을 왔는데 직장 상사에게 전화가 왔어. 어디냐고 묻더라고 그래서 나는 말했지. 저 여행왔는데요. 여기는 ___
- 모스크바에 여행을 왔는데 건물도 예쁘고 먹을 것도 맛있었어. 날씨도 너무 좋아. 오늘 점심으로는 샌드위치를 사서 공원에서 먹었어. 그런데 글쎄 직장 상사한테 전화가 왔어. 어디냐고 묻더라구 그래서 나는 말했지. 저 여행왔는데요.여기는 ___
후자 문장의 단어를 예측하는 것을 더 힘들어한다. 예측하기 위해서는 첫 단어인 “모스크바”를 기억해야 하는데, 문장이 길어지면서 gradient exploding/gradient vanishing 현상이 발생하여 정보가 소실될 가능성이 높기 때문이다.
Gradient exploding 문제는 Gradient clipping으로 어느정도 해결될 수 있는데, 이것은 Gradient의 상한선 임계값 (threshold)을 지정하여 발산을 피하는 것을 의미한다. 하지만 Gradient vanishing 문제는 이렇게 쉽게 해결되는 문제가 아니기 때문에 여러 모델 구조가 등장한다.
2-2. LSTM (Long Short Term Memory)
2-1에서 말한 vanishing gradient problem을 해결하기 위해 나온 모델 구조이다.

LSTM의 핵심 아이디어는 얼마나 정보를 가져갈지 / 잊을지를 조절하는 “gate”라는 개념을 도입하여 곱셈 연산을 덧셈 연산으로 바꾸는 것이다. 각 구조별로 어떻게 계산이 이루어지는지 살펴보자. 이해의 편의를 위해 최종 과정부터 소급해가는 식으로 설명하겠다.
(1) final memory cell (ct)

위 식을 풀어서 설명하자면, 이전 값(ct-1)을 얼마나 잊을지(f), 이번에 들어온 입력값(i)을 얼마나 기억할지(g)를 구하고 이 둘을 더하는 것이다.
(2) final hidden cell (ht)
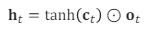
(1)에서 구한 final memory cell에 활성화함수를 곱하고, output gate를 곱해준다.
(3), (4), (5)는 유사한 형태이지만 서로 역할과 가중치가 다르다.
(3) forget gate (ft)

과거 정보를 얼마나 잊을지 정하는 게이트이다. 이것은 가중치와 곱하여 구해진다. (W, U)
(4) input gate (it)
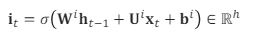
들어온 입력 값을 얼마나 반영할지 정하는 게이트이다.
(5) output gate (ot)
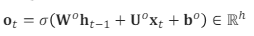
다음 셀로 정보를 얼마나 내보낼지를 정하는 게이트이다.
LSTM은 Vanishing gradient problem을 효과적으로 완화하는 효과를 가진다. gate를 통해 기억할 정보와 잊을 정보를 나눠서 관리함으로써, 이전의 정보가 중요하게 판단된다면, 완전히 보존되는 상태로 hidden state를 갱신해나갈 수 있기 때문이다. 다만 구조가 복잡하며 RNN보다 학습 파라미터가 많아진다는 단점을 가지고 있다.
2-3. GRU (Gated Recyrrebt Units)

GRU는 LSTM과 유사한 성능을 가지지만 gate의 개수가 3개에서 2개로 줄어 학습 시간을 줄일 수 있다는 이점이 있다.

new hidden state (ht)
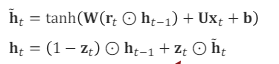
LSTM에서는 f, i 두개의 gate로 관리했었는데, 여기서는 한개의 게이트를 (1-z), z로 사용한다.
⇒ 즉 과거의 정보와 현재의 정보를 양자택일한다고 생각하면 된다.
update gate (zt)

이전 상태와 현재 상태를 얼마만큼의 비율로 반영할지를 결정한다.
LSTM에서 input gate, forget gate를 update gate로 합쳤다고 생각하면 된다.
reset gate (rt)

이전 상태를 얼마나 반영할지를 결정한다. LSTM의 output gate라고 생각하면 된다.
참고자료
- 인간언어기술개론 수업
- https://www.ibm.com/kr-ko/topics/recurrent-neural-networks
순환 신경망이란? | IBM
순환 신경망(Recurrent Neural Networks, RNN)이 순차 데이터를 사용하여 언어 번역과 음성 인식에서 나타나는 일반적인 시간 문제를 어떻게 해결하는지 알아봅니다.
www.ibm.com
- https://www.youtube.com/watch?v=006BjyZicCo