
*다음 내용은 Andrew ng의 Deep Learning Specialization 과정 중 일부 강좌를 정리한 강의 노트입니다. 틀린 내용이 있다면 말씀해주세요.
what is a neural network?


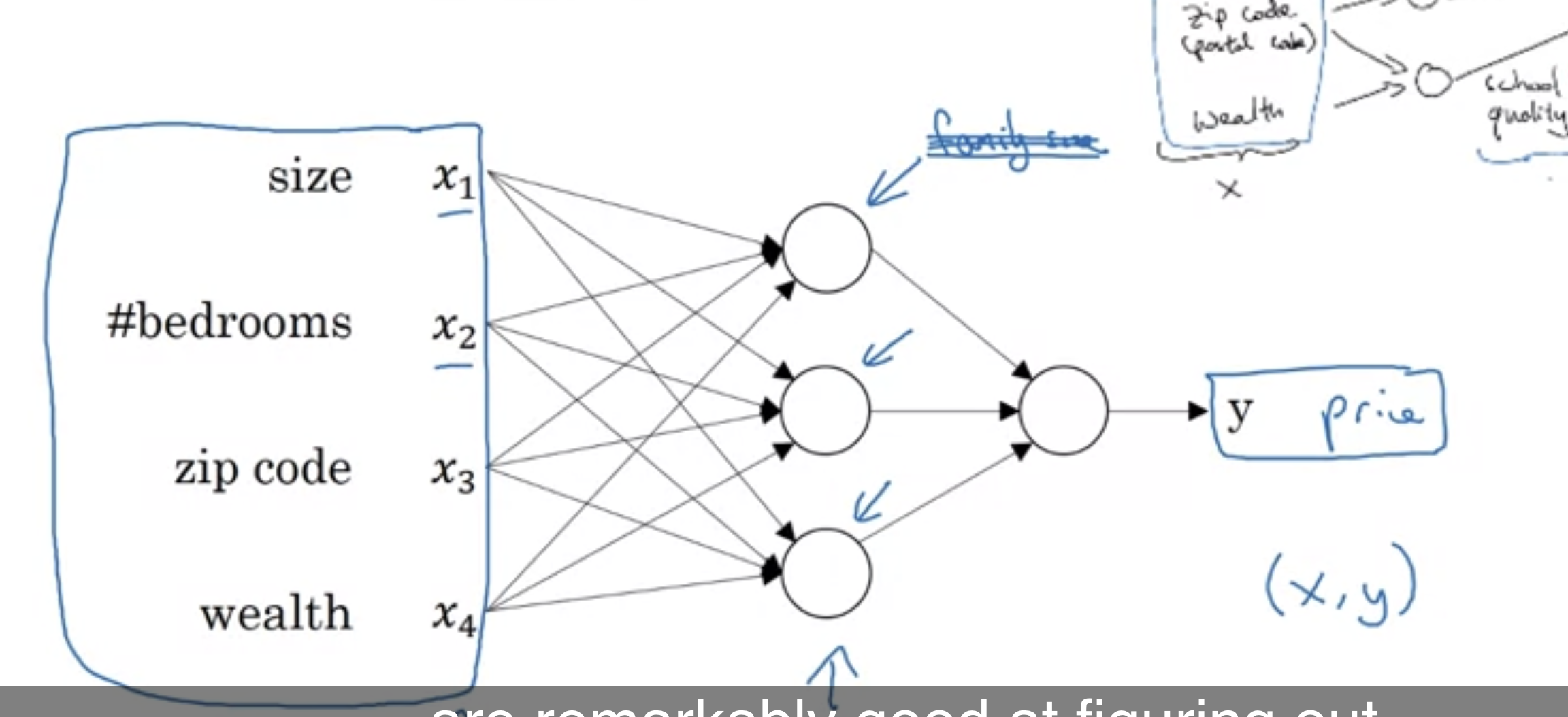
집의 크기가 X축이자 입력, 집의 가격을 Y축이자 출력이라고 하자. 그리고 뉴런은 그 사이 과정에 있는 선형 함수이다. 보통 활성화 함수로 ReLU (Rectified liner unit) 함수를 사용하는데, 이에 대해서는 추후에 더 자세히 살펴볼 것이다. 이러한 하나의 뉴런이 레고 블럭이라면 신경망은 이러한 레고 블럭의 집합(stacking)이라고 할 수 있다. 그 예시는 다음과 같다.

실제 상황에서는 집의 크기만 고려하는 것이 아니라 침대의 개수, 위치 등등의 정보를 이용해서 가격을 예측할 것이다. 그래서 이러한 정보들이 X가 되고, price가 Y가 된다. 그 사이에 있는 뉴런들은 모델이 스스로 학습하면서 형성된다.
Supervised Learning with Neural Networks
이번 강의에서는 neural network를 활용한 supervised learning이 어떻게 활용되는지를 살펴볼 것이다.


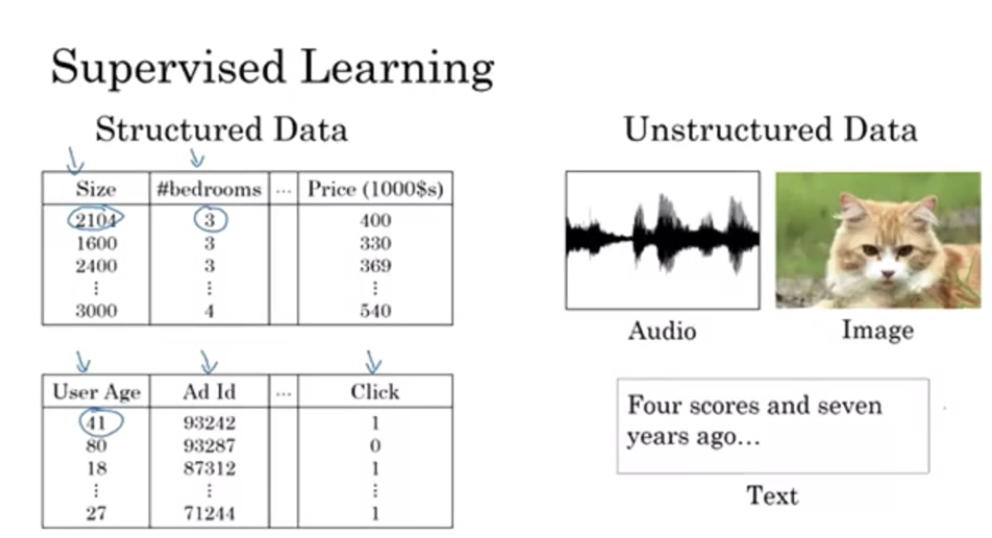
structured data는 기존 데이터베이스 자료들을 의미하고, unstructured data는 음성, 이미지, 텍스트들을 의미한다. 사람들은 비정형 데이터를 익히는데에 능숙하지만, 컴퓨터는 정형 데이터들에 비해 비정형데이터들을 다루는데 능숙하지 않았다. 그러나 딥러닝을 통해 그것을 가능하게 해주고 있다. 무엇을 입력값으로 두고, 무엇을 출력값으로 두어 창출해낼 것인지에 대해 생각해보자.
Why is Deep Learning taking off?
사실, 딥러닝에 대한 기술적인 이야기는 수십년이 되어왔다. 그런데 왜 이제서야 주목을 받고 있는 것일까?

여기서 x축은 (labeled) 데이터의 양을, y축은 성능을 의미한다. 데이터의 양과 성능은 비례관계를 보이는데, 현대에 들어와 디지털 시대가 되면서 데이터 양이 증가했다. 즉, 과거에 이러한 기술을 개발하더라도 데이터가 많지 않으면 성능이 높지 않기때문에 소용이 없었다. 또한, 신경망의 크기가 크고 더 좋은 성능의 컴퓨터로 학습시킬수록 성능이 높아진다. 그런데 과거에는 컴퓨터 성능이 지금보다 안좋았기때문에 학습시키기 힘들었을 것이다.
또한, 데이터가 작을 때는 구현자의 알고리즘에 따라 성능이 달라질 수 있으나, 데이터가 많아질 경우에는 큰 신경망일수록 성능이 높아진다.

위에서 언급한 data와 computation 외에도, algorithm의 발전으로 더 빠르게 계산이 가능해졌다. 예를 들면 활성화 함수가 sigmoid함수에서 ReLU로 바뀐 것이 있다. sigmoid 함수같은 경우 기울기가 0에 가까워 학습 속도가 굉장히 느려진다. ReLU 함수로 바뀌면서 gradient descent 알고리즘을 더 빠르게 작동하도록 했다.
또한, 딥러닝은 굉장히 반복적인 성격을 띄고 있다. (Idea->Code->Experiment) 따라서 훈련하는 데에 굉장히 오래 걸린다. 위 사이클을 계속 돌리다보면 시간이 오래 걸리게 되는데 계산 속도 자체의 발전으로 속도 개선이 이루어졌다. 알고리즘, 하드웨어, 데이터로 인해 딥러닝은 계속해서 발전하고 있다.
'Deep Learning Specialization 강의 > Neural Networks and Deep Learning' 카테고리의 다른 글
| Deep Neural Networks (4주차) 정리 (0) | 2024.07.11 |
|---|---|
| Shallow Neural Network (3주차) 정리 (0) | 2024.07.11 |
| Logistic Regression as a Neural Network (2주차) 정리 (0) | 2024.07.08 |